关于HTTP协议:
HTTP是建立在TCP协议之上,HTTP协议的瓶颈及其优化技巧都是基于TCP协议本身的特性,例如:
TCP 建立连接的3次握手和断开连接的4次挥手以及每次建立连接带来的RTT延迟时间。
影响HTTP网络请求的因素主要有两个: 带宽和延迟
带宽:现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
延迟:
- 浏览器阻塞(HOL blocking):浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
- DNS 查询(DNS Lookup):浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的
- 建立连接(Initial connection):HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。

关于连接
怎么算是一个连接,HTTP 1.1 出现的keep-alive
每次连接都要经历三次握手和慢启动,说明HTTP的连接实际上是TCP 的连接。
HTTP1.0和HTTP1.1的一些区别:
1.缓存处理:
HTTP1.0header使用 If-Modified-Since,Expires 等作为缓存标准的判断,HTTP1.1 引入更多的缓存策略: Entity tag, If-UnModified-Since ,If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略
2.带宽优化及网络连接
HTTP1.0存在一些浪费带宽的情况,HTTP1.1 添加了头部中的range,客户端可以请求资源的一部分,返回响应码(206 Partial content)
3.错误处理的通知
新增错误处理通知的状态码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除
409冲突:
由于与目标资源的当前状态冲突,无法完成请求。此代码用于用户可能能够解决冲突并重新提交请求的情况。
服务器应该生成一个有效负载,其中包含足够的信息供用户识别冲突源。
冲突最有可能发生在响应PUT请求时。例如,如果正在使用版本控制并且包含PUT的表示更改为与早期(第三方)请求冲突的资源,则源服务器可能使用409响应来指示它无法完成请求。在这种情况下,响应表示可能包含对基于修订历史合并差异有用的信息。
410(gone)
410 Gone客户端错误响应代码表示在源服务器上不再可以访问目标资源,(永久删除)并且此条件可能是永久性的。
如果您不知道此缺失是暂时的还是永久性的,
404则应使用状态代码。
put请求:与post区别
put请求用于更新资源
post用于创建资源
4.Host 头处理
添加请求的主机名,HTTP1.0 的版本,认为每个IP与一个主机对应的,但是由于虚拟主机的出现,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址,所以新增了主机名
5.长连接
HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。以下是常见的HTTP1.0:


HTTP1.0 ,1.1现存的一些问题
1.HTTP1.x在传输数据时,每次都需要重新建立连接,无疑增加了大量的延迟时间,特别是在移动端更为突出
2.HTTP1.x在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,这在一定程度上无法保证数据的安全性
3. HTTP1.x在使用时,header里携带的内容过大,在一定程度上增加了传输的成本,并且每次请求header基本不怎么变化,尤其在移动端增加用户流量
4.虽然HTTP1.x支持了keep-alive,来弥补多次创建连接产生的延迟,但是keep-alive使用多了同样会给服务端带来大量的性能压力,并且对于单个文件被不断请求的服务(例如图片存放网站),keep-alive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
SPDY
使用SPDY加快网站速度
2012年google提出了SPDY的方案,大家才开始从正面看待和解决老版本HTTP协议本身的问题,SPDY可以说是综合了HTTPS和HTTP两者有点于一体的传输协议,主要解决:
- 降低延迟,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
- 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
- header压缩。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
- 基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
- 服务端推送(server push),采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。SPDY构成图
HTTP
SPDY
SSL
TCP
SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTTP协议(将HTTP1.x的内容封装成一种新的frame格式),同时可以使用已有的SSL功能。
HTTP2.0的前世今生
顾名思义有了HTTP1.x,那么HTTP2.0也就顺理成章的出现了。HTTP2.0可以说是SPDY的升级版(其实原本也是基于SPDY设计的),但是,HTTP2.0 跟 SPDY 仍有不同的地方,主要是以下两点:
HTTP/2介绍
在与 HTTP/1.1 完全语义兼容的基础上,进一步减少了网络延迟,大幅度的提升了 web 性能。
特性
1.多路复用(Multiplexing)
以下描述我认为相当准确
允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。
HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。
简而言之:
HTTP/2 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流
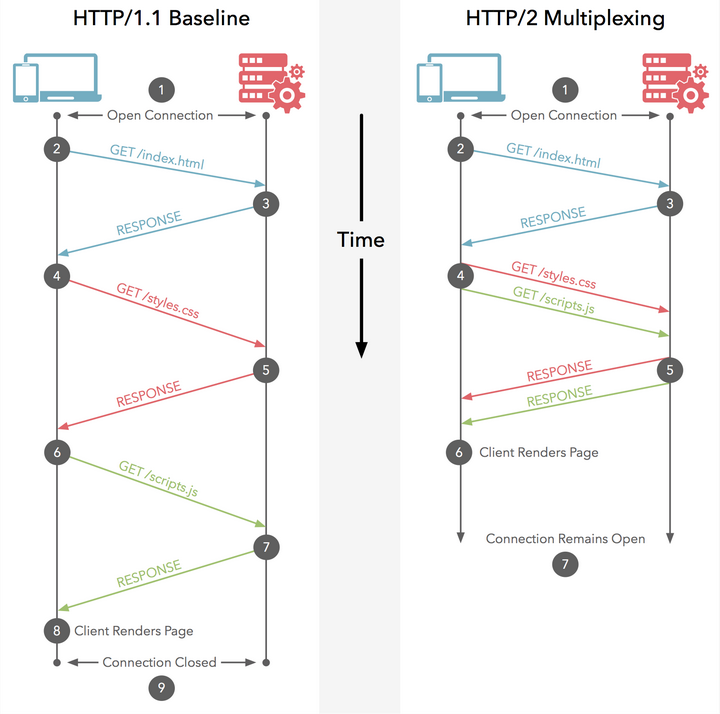
原理:

HTTP 1.x之前是:
更详细的描述多路复用:
2.二进制分帧
Binary protocols are more efficient to parse, more compact “on the wire”, and most importantly, they are much less error-prone, compared to textual protocols like HTTP/1.x, because they often have a number of affordances to “help” with things like whitespace handling, capitalization, line endings, blank lines and so on.
For example, HTTP/1.1 defines four different ways to parse a message; in HTTP/2, there’s just one code path.
It’s true that HTTP/2 isn’t usable through telnet, but we already have some tool support, such as a Wireshark plugin.
they often have a number of to “help” with things like whitespace handling, capitalization, line endings, blank lines and so on.
TTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
使用二进制传输的好处在于它更接近于计算机存储特点,传统的文本流传输形式存在一些解析上的复杂性,如对消息长度(Message Length)的解析要分为4种情况,详见w3c,而使用二进制方式则不存在这个问题。需要注意的是http/2的二进制形式并没有改变http/1.1的体系,只是把传输报文格式改了
【突破 HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量】 关键之一是在应用层(HTTP/2)和传输层(TCP or UDP)之间增加一个二进制分帧层。
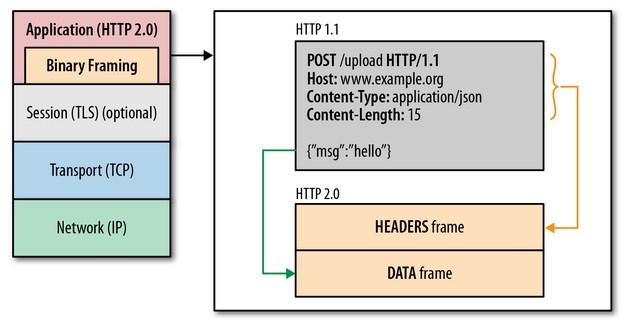
二进制分帧层将所有的传输消息分为更小的消息和帧(frame),并对他们采用二进制格式的编码,其中HTTP1.x中的受不信息会被封装到HEADER frame 中相对的Request body被封装到 DATA frame 中
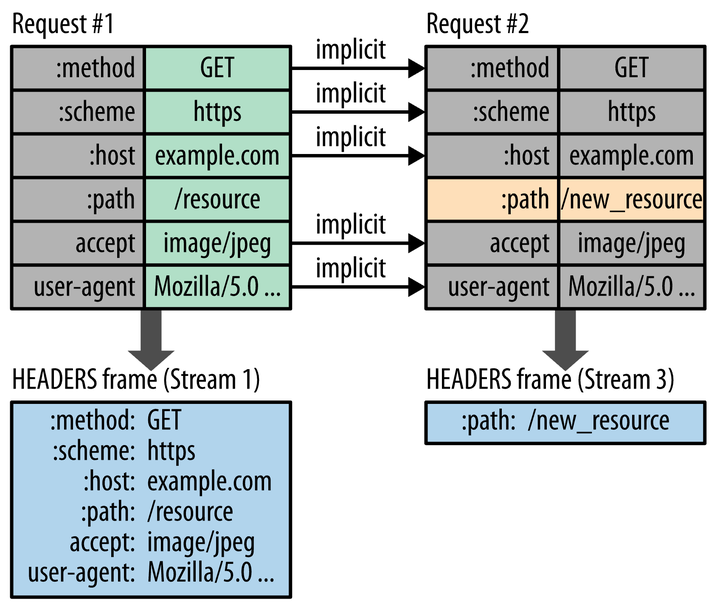
客户端发了两次请求,第一次请求有完整的http报文头部,第二次请求的时候只有一个path的字段不一样,但是这次报文头它只需要发送一个path的字段就好了,这样就大大减少了发送的量。这个的实现要求客户端和服务同时维护一个报文头表。上面提到的少了4kb的流量很可能是这个节省下来的。这个的意义还是很大的,因为动态请求有时候可能只需要发送几个字节的数据,但却需要发送一个几百个字节的报文头(500 ~ 800)
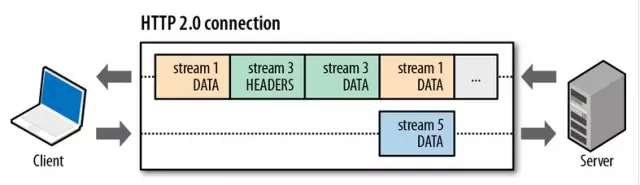
通信都在一个连接上完车给,这个连接可以承载任意数量的双向流。
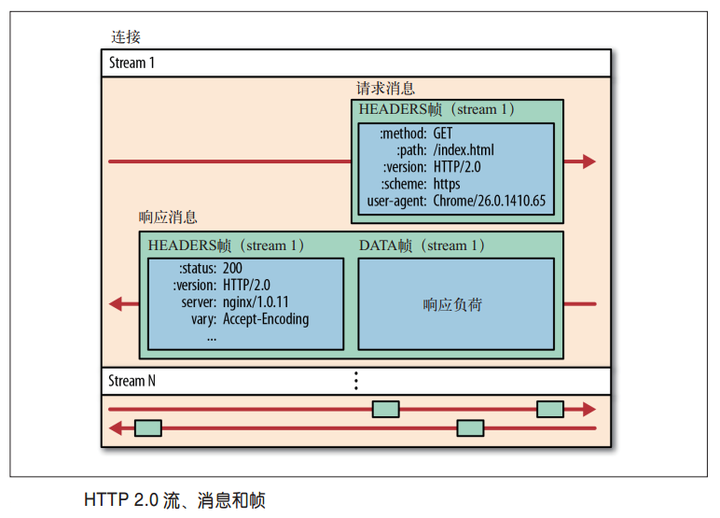
实现低延迟的关键是二进制分帧,那么导致低延迟的原因是TCP连接的
慢启动:
刚建立的连接不宜发送大量的数据,会导致路由器缓存空间耗尽,所以选择根据网络中的状况逐步增加每次发送的数量,cwnd(拥塞窗口)动态变化。
起初 拥塞窗口和接收窗口一样 都是1 ,每收到一个确认,就让拥塞窗口扩大2倍,直至到 门限值(16),然后使用加法增大 每收到1个确认,将拥塞窗口+1,直到网络拥塞
拥塞避免
然后,改变门限值为拥塞时候值的一半,拥塞窗口置为1,然后让它再次重复,这时一瞬间会将网络中的数据量大量降低。
当cwnd<ssthresh时,使用慢开始算法。
当cwnd>ssthresh时,改用拥塞避免算法。
拥塞避免算法让拥塞窗口缓慢增长,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口按线性规律缓慢增长。
无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认,虽然没有收到确认可能是其他原因的分组丢失,但是因为

无法判定,所以都当做拥塞来处理),就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为1,执行慢开始算法。
另外,还有TCP的
快速重传
快重传可以提高网络的吞吐量而快恢复算法相当于拥塞避免算法的后半恢复部分的优化.
假设以下情况:如果在发送方设置的超时定时器到时间还没有收到确认,那么有一种可能是网络发生堵塞,这种情况下,tcp会将拥塞窗口置为一,新的门限值变为发生阻塞时的一半并且开始执行慢开始算法.当我们使用快重传的时候,要求接收方接收到一个失序的报文段后就立即发出 重复确认,(目的是让对方早知道有报文段没有到达)
假设发送方发送了M1–M4四个分组,接收方收到了M1和M2,以及M4,这些分组.
现在接收方不能确认M4,因为M3没有收到,此时接收方可以什么都不干,也可以发送对M2的确认,但是快重传算法要求这样做:
接收方应该及时发送对M2的重复确认,这样可以让发送方知道M3并没有被传过来,发送方还会试着发送M5,M6,接收方收到之后,我们会继续发送对M2的确认,这样一共发了好几个对M2的确认,按照规定,只要发送方收到三个重复确认,就立即重传对方未收到的报文段M3.这样可以避免阻塞,并且提高我们网络的吞吐量.

快速恢复
当发送方收到三个连续确认时,就执行”乘法减小”算法,把”慢开始门限”减半,注意接下来不会执行慢开始算法.
由于此时没有发送网络阻塞(要是发生阻塞的话就不会连续收到4个确认),因此此时不执行慢开始算法,并不会将拥塞窗口的值置为1,而是将它置为慢开始门限的一半.然后再实行拥塞避免算法,每次收到确认之后+1.
快重传配合使用的还有快恢复算法,有以下两个要点:
①当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半。但是接下去并不执行慢开始算法。
②考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法。
发送方窗口的上限值
接收方的缓存空间总是有限的。接收方根据自己的接收能力设定了接收窗口rwnd,并把这个窗口值写入TCP首部中的窗口字段,传送给发送方。因此接收窗口又称为通知窗口(advertised window)。因此,从接收方对发送方的流量控制的角度考虑,发送方的发送窗口一定不能超过对方给出的接收窗口值rwnd。
发送方窗口的上限值=Min [rwnd,cwnd]
当rwnd<cwnd时,是接收方的接收能力限制发送方窗口的最大值。
反之,当cwnd<rwnd时,则是网络的拥塞控制发送方窗口的最大值。
也就是说,rwnd和cwnd中较小的一个控制发送方发送数据的速率
以上也是TCP为了防止网络拥塞的情况提出的拥塞控制的机制:
近些年又出现了选择性应答:
继续二进制分帧:
HTTP/2让所有数据流共用一个连接,可以更有效的使用TCP连接,
- 单连接多资源的方式,减少服务端的连接压力,内存占用比较少。连接吞吐量更大。
- TCP连接的减少使得网络拥塞状况得到改善,慢启动减少,使得丢包和拥塞恢复速度更快。
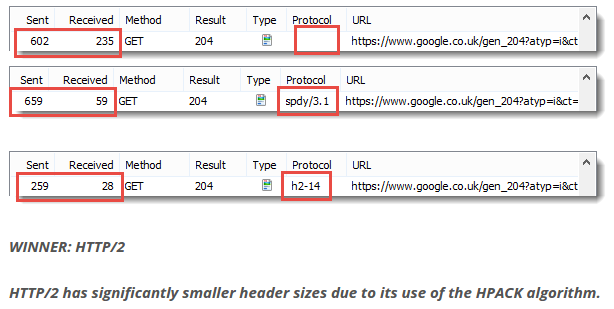
3.首部压缩(Header Compression)
移除了请求中的一些啰嗦首部,你可以通过很少的 IP package,承载数十个乃至上百个的请求,更符合最小数据量的理想化原则。
HTTP 1.1 不支持首部压缩,SPDY和HTTP2.0应运而生,SPDY 使用通用的DEFATE算法,HTTP/2.0使用专门为压缩首部设计的HPACk算法
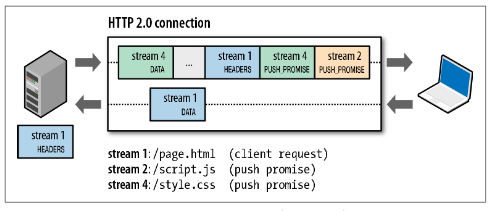
4.服务端推送(Server push)
服务端会向客户端发送 CSS,JavaScript 以及图片文件,而无需通知客户端,服务端知道客户端可能会需要什么。所以它使用 Server Push 发送多个响应给客户端。节省了 Round Trip ,此时就变成了一个Less chatty 的协议,同时也充分的利用了网络资源
在客户端请求之前发送数据,服务端可以
- 对客户端的一个请求发送多个响应,对于一个主页发起的请求,服务端会响应主页请求、logo、style样式这些客户端会用到的东西,相当于在一个HTML 文档中集合了所有的资源。
- 缓存
在同源情况下,不同页面之间可以共享缓存资源
HTTP 1.1 协议 请求内容
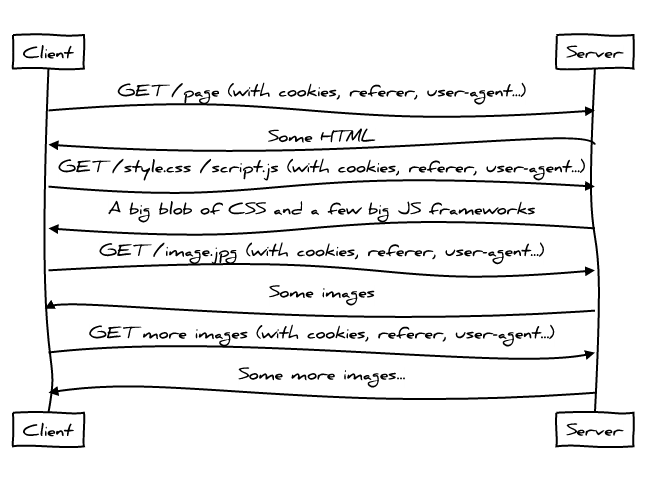
- HTTP/1 是繁琐(chatty)的协议需要不断去向服务端请求新的东西,首先是 HTML 然后是 CSS Javascript 每一次的交换都增加了往返的延迟
- 每次请求都携带了大量的数据,应该尽可能少的发送数据给服务器,Referer、User-Agent 都是啰嗦的首部
- 线头阻塞 看似性能提升的 css sprite inline image ,下载的数据往往超过客户端展示的数据
关键是何时Push
因为 push 具有投机性,会出现 push 过去的东西,浏览器可能不需要
这种情况下,HTTP/2 允许客户端通过RESET_STREAM主动取消 Push ,然而这样的话,原本可以用于更好方向的 Push 就白白的浪费掉数据往返的价值。
HTTP /2 的server push 及HTTP/2 的缓存策略
HTTP/2 缓存策略 + Cache Digests
问题
如果客户端已经在缓存中有了一份 copy 怎么办,还要 push 吗
- 客户端使用缓存摘要告诉服务端 某些东西已经缓存
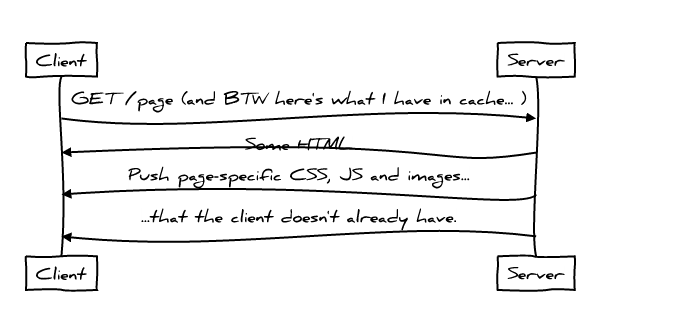
Cache Digest 使用的是 Golumb Compressed Sets
浏览器客户端可以通过一个连接发送少于 1K 字节的 Packets 给服务端,通知哪些是已经在缓存中存在的。
TCP
在 HTTP 开始之前 TCP 需要进行三次握手,来协商新连接的参数。这意味着在建立连接的时候,一个最简单的 HTTP 请求也需要 2 个 Round-Trip Time 才能完成 。
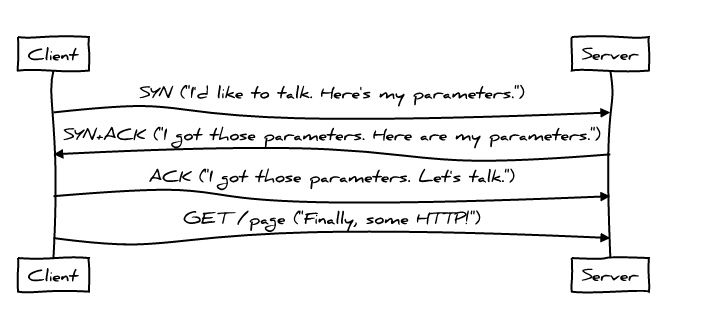
TCP Fast Open 允许应用在 TCP 握手期间(SYN 和 SYN+ACK packets)交换数据,这样可以减少一次 RTT,不幸的是目前只支持 Linux 以及 OSX,未来 TFO 在 HTTP上将会有更多巧妙的运用
TFO 不保证与 SYN 数据包发送的数据将只出现一次;这是容易重复(由于重传),甚至被恶意的重放攻击。 因此,在一个 TFO 连接上使用 HTTP POST 并不是建立第一个请求的好主意。 并且,使用 GET 也依然会有很大的副作用,浏览器也没有好的办法来检测哪个 URL 可以做到这一点的
TLS
在传输应用数据之前,客户端必须与服务端协商密钥、加密算法等信息,服务端还要把自己的证书发给客户端表明其身份,这些环节构成 TLS 握手过程,还没把客户端和服务端处理时间算进去。光是 TLS 握手就需要消耗两个 RTT(Round-Trip Time,往返时间)
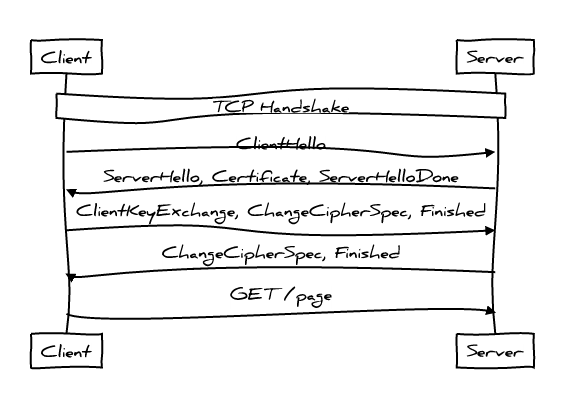
而 Session Tickets 可以将 TLS 握手所需 RTT 减少到 1 个:
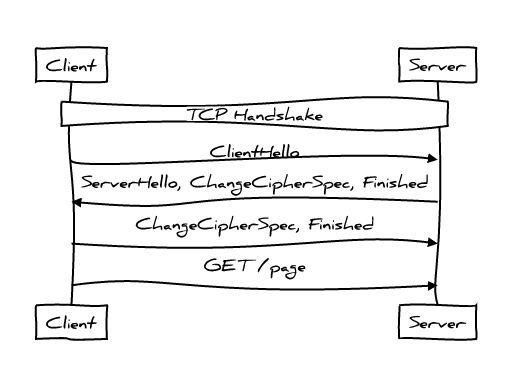
不久的未来,TLS 1.3 将会支持 Zero Round Trip 握手,HTTP 可以在第一个 Round Trip 就发送数据。